概要
動画から機械学習モデルを作るとき、一番時間を食うのがアノテーションではないでしょうか。
何枚か画像を抜き出してラベリングをするのですが、動きの速い動物の動画などだと前後のフレームを見比べないとその時どんな行動しているのかがわからなかったりする。
でもって、ラベリングツールとして有名ドコロだとMicrosoft謹製のVoTTやAWSのGroundTruthなどがあるかと思いますが、いずれもバウンディングボックスのアノテーションがメインで、意外にも単純な「フレームごとに何をしているのか、何が写っているか」みたいなシーン・フレームに対するアノテーションを動画で行うツールというのは私の知っている限りはない(誰か知っていたら教えてほしい)。
無いなら作るしか無い!ということで、たまたまDeepLabCut関連で知ったPythonの画像ビューワライブラリであるnapariを使って、超単純な動画アノテーションツールを作ってみたというお話。
もう作ってから数ヶ月経ってしまいましたが、あまりnapariに関する日本語の記事がないのでメモ程度に書いておきます。
まとめ
- コードはこちら
napariはPythonを知っている人なら気軽にカスタマイズできる、高速でスタック画像に強い画像ビューワ。
- daskを使って分散的に画像処理を行っているなどかなりパフォーマンスに気を使って設計されており、Z-stackや大きな画像の操作もキビキビしているモダンなビューワ
- 複数の画像をレイヤーとして扱うことができ多重染色画像のマージした表示が可能だったり、立体画像の3Dレンダリングができたり、Drawingができたりバニラでも多機能なビューワ
- 類似のものとして過去の資産もあるので未だにImageJは優れたツールだが、napariは積極的に更新が行われておりかなり勢いがあるように感じる。
すでにnapariを使った様々な作例があるので、それらを参考にすれば色々と作れそう
- DeepLabCutのようなPoint annotation、single cell trackingなどの例あり。
- Pythonの自作関数をキーバインドに割り当てられる
また、napariに関する日本語記事として、次の記事がとても参考になると思います(実は私もたまたまこれを見て触発されたので今更ながらブログを書いていたり)。
注意事項
先にも書いたとおり、とても開発が活発かつまだα版であり、今書いた内容がいつまで通用するかわかりません。
また、APIの破壊的な変更が起こりうるので、最新情報は公式のGitHubやドキュメントを参考にしてください。
作ったもの
GitHubのReadmeに書いたとおりではあるのですが、要は動画から↓こんな感じのCSVを作るためのもの。
frame, behavior 1, behaviorA 2, behaviorA 3, behaviorA 4, behaviorA ..., ... 98, behaviorA 99, behaviorA 100, behaviorB 101, behaviorB 102, behaviorB ..., ...
操作イメージとしては、
config.yamlファイルに開きたい動画ファイルとアノテーションしたい行動の名前を書き、python behavior_annotator.pyで起動- 行動の開始フレームで'f'キーを押し、フラグを設定
- 行動の終わりまでスライダーを動かし、
1または2キーを押すことで、フラグのあるところからスライダーのあるところまでを一気にアノテーション!
を繰り返すものです。意外にもこういうアノテーションができるものが私の知っている限り無かったんですよね。動物の行動は連続して行われるので、1枚ずつチマチマ行動A、行動A、行動A……って分類していくのはしんどくて、行動開始地点からまとめて指定できるのが欲しい機能でした。
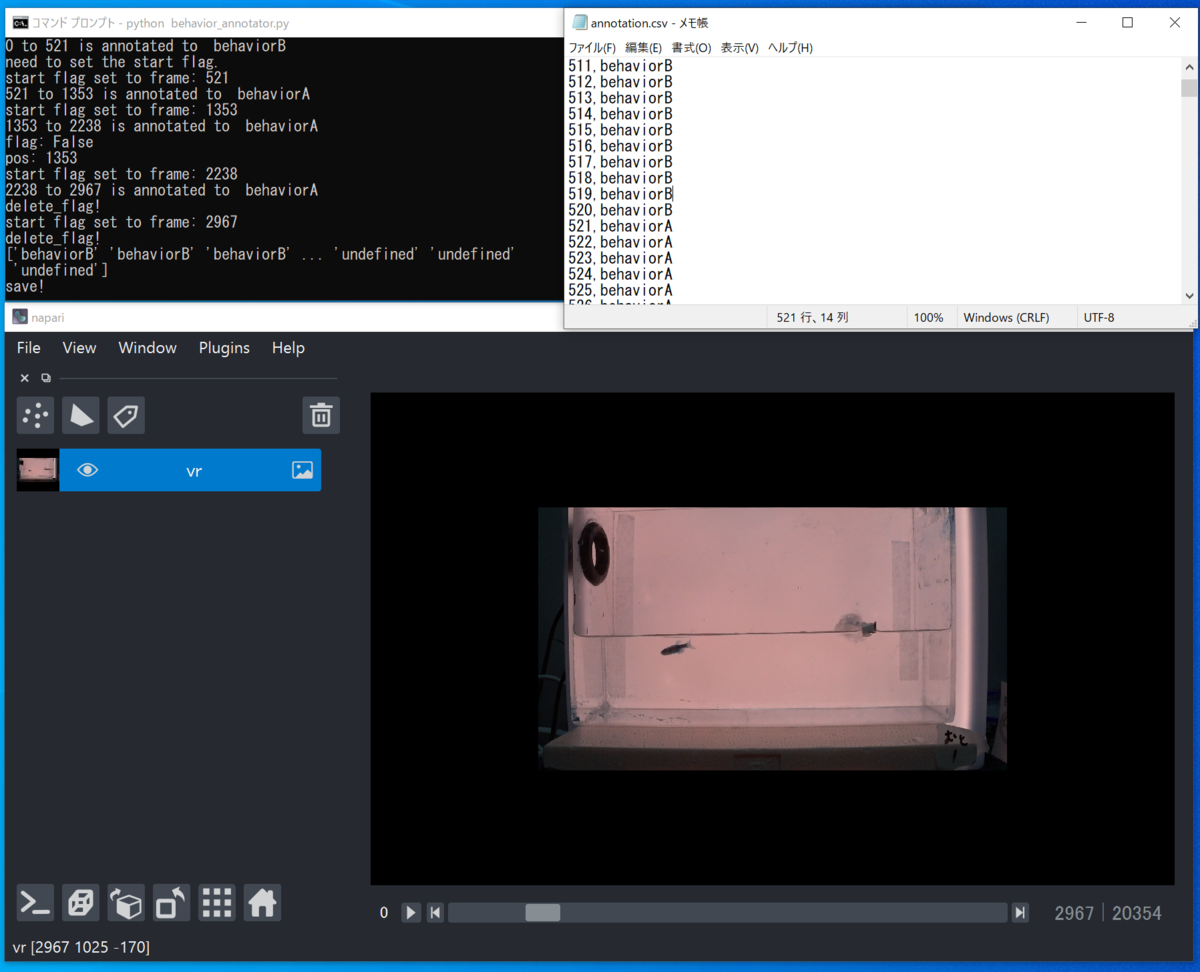
最後までラベリングが終わったら0キーを押すことで、pandas.to_csvによって上記のようなCSVが作成されます。
また、作成時の工夫として、napari標準の機能で動画を読み込むとものによっては非常に重い(この問題は作者たちも認識しているようで、いずれ改善されるかもしれません)ので、別の方が作られているOpenCVを使ったnapari用の動画ローダーであるnapari-videoを使用しています。
コードを見てもらえればわかるのですが、napariを使うことでこんなリッチな画像ビューワのGUIが数行で立ち上がり、合計数十行で自分のほしい機能を実装した動画アノテーションツールを作ることができるのです!napariすごい。
まあ私の作例は全然しょぼいしnapariの機能の1%も使えていないのですが。誰かの何かの参考になれば幸いです。