概要
以前こちらの記事で書いたように、DirectXを介して機械学習系の演算を行うことで、CUDAが使えるnvidiaのGPUに限らず、DirectX12に対応するあらゆるGPUにおいて機械学習を高速化できるというmicrosoftのDirectMLというプロジェクトがある。(ただし、DirectXを使うことからわかるように、WindowsまたはWSLのみで利用可能であることに注意!)
このDirectMLを使った実例の一つとして、DirectMLによってTensorFlowを高速化した、tensorflow-directmlというパッケージが存在。TensorFlow 1.15互換で、CUDAのインストールのようなややこしい手順なしに、ただpip install tensorflow-directmlを実行するだけで、nvidia, AMD, Intelなどメーカーに限らずGPUを使ったTensorFlowの高速化が可能という素晴らしいパッケージであった。
ただ、今更TensorFlowの1.15を使わなければいけないのはしんどい。
TensorFlow-DirectMLのGitHubページではいずれTensorFlow2に対応予定と書いてあったので、RX6900XT持ちでTF2使いの私はそのリリースを今か今かと待ち望んで定期的にウォッチしていたのですが、なんと本日2022/6/23にtensorflow-directml-pluginなるTF2のPluggable DeviceとしてDMLのGPUを認識させるプラグインがプレビューながらリリースされたのでした。
まだ出たばかりで実用に耐えうるものとは思いませんが、とりあえず使ってみたメモを書いてみます。
まとめ
- DirectML + TensorFlow2の環境構築は、次の2行でサクッとできます(既存環境に影響ないように、必ず仮想環境作ってから実行しましょう)。
pip install tensorflow-cpupip install tensorflow-directml-plugin
※(20221228追記) TensorFlow2.11からはGPU版のTensorflowがpipで配信されなくなったため、pip install tensorflowで大丈夫です。古いバージョンを利用したいときは明示的にpip install tensorflow-cpu==2.x.xなどと指定するほうが安全かも。
- Requirementは、Windows 10 Version 1709, 64-bit (Build 16299 or higher)、TensorFlow2.9以上、Python3.7以上
- AMD RX6900XTで試してみたところ、MobileNetの学習がCPU(Ryzen5 5600X, 6core)の10倍近く高速化できることを確認!
- 残念ながら、まだ非対応の演算も存在する模様。今回試したテストプログラムの中では、
tf.keras.layers.preprocessing.RandomFlipのような、Layerを使ったAugmentationでエラーが出てしまった。- いずれ修正されるものと願っていますが、今のところはAugmentationをDataloader部分で実装するなどして対応するしかなさそう。
ちなみに、以前の記事でも書きましたが、DirectMLをnvidiaのGPUで使うこともでき、CUDAやらインストールしなくてもGPUを使えるようになりますが、パフォーマンス劣化があります(演算の種類にもよりますが通常のCUDAの1/3ほどになってしまう)。
ですので、基本的にはWindowsでAMD/Intel GPUを使ってる人のみが対象になるかと思います。
tensorflow-directml-pluginが出るまでの流れをちょっと書いてみる
私がこのDirectML関連の存在を知ったのは最初の記事を書いた2021/1頃なのですが、そこから定期的にTF2対応に関する議論をウォッチしていたので、一応Pluggable DeviceとしてDMLが実装されるまでの情報源を知る限りでメモっておく。なんの役に立つかは知らない。
2020/5~2022/3 Tensorflow CommunityでのDirectML上でTensorFlowを動かすことに関するRFC
- だいぶ長いこと議論されており、実際にAcceptされるまで2年近くかかっている。
- 途中で後述のPluggable Deviceを利用した実装にシフトしたよう。
- RFC: TensorFlow on DirectML by wchao1115 · Pull Request #243 · tensorflow/community · GitHub
- community/20200511-tensorflow-on-directml.md at eff9c820a2c3dace1bb590e1447dd40871a7a80f · tensorflow/community · GitHub
2020/6~9 Tensorflow CommunityでのPluggable Device追加に関するRFC
- Pluggable Deviceが何なのか、TFのAPIに精通しているわけではないので詳しくは知りませんが、"pluggable device mechanism which allows to run existing TensorFlow programs on a new device without user changing the code. (既存のTFのプログラムをコードを変更することなく新しいデバイス上で動かすためのメカニズム)"とのこと。
- ここにMicrosoftの関係者も参加していたよう。
- RFC: Adding Pluggable Device For TensorFlow by jzhoulon · Pull Request #262 · tensorflow/community · GitHub
- ここに図とかあります: community/20200624-pluggable-device-for-tensorflow.md at 410c44d3559bdec311af46d8224fc55f518729d5 · tensorflow/community · GitHub
2022/3~ TensorFlow2.9に合わせて、Pluggable Device+DMLをTensorFlow上で動かすためのコミットが複数行われる
2022/4 突如DirectMLのリポジトリにTensorFlow2を使ったサンプルが追加される
- このときは「いよいよ来たか!」とワクワクしたものの、肝心の
tensorflow-directml-pluginの導入方法が記されておらず試すことができなかった - Add TF2 versions of TF sample models (#225) · microsoft/DirectML@09f0262 · GitHub
- このときは「いよいよ来たか!」とワクワクしたものの、肝心の
2022/6
tensorflow-directml-pluginがプレリリース
インストール方法の詳細
公式のドキュメントは一応こちら。BUILD.mdにはソースからのビルド方法もありますが、pypiに tensorflow-directml-pluginが登録されているのでただ試すだけならこちらを使ったほうが楽。
仮想環境作成&アクティベーション
コマンドプロンプト起動して以下を実行。Anaconda使っている人はそちらでも良い。
python -m venv にんいのなまえ "仮想環境作った場所までのパス\にんいのなまえ\Scripts\activate.bat"
TensorFlowとtensorflow-directml-pluginのインストール
一応ここに書いてある内容を参考。
pip install tensorflow-cpu pip install tensorflow-directml-plugin
インストールのチェック
PythonのREPLを起動して、次の2行を実行(参考: https://thr3a.hatenablog.com/entry/20180113/1515820265) 。
from tensorflow.python.client import device_lib device_lib.list_local_devices()
すると、次のような出力がずらずらと出てくる。DirectMLやらpluggable_deviceやらキーワードっぽいのがたまに紛れてます。
device:GPU:0の項目に、physical_device_desc: "device: 0, name: DML, pci bus id: <undefined>として認識されていることがわかります。
2022-06-23 18:49:20.701865: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-06-23 18:49:20.702369: I tensorflow/c/logging.cc:34] DirectML: creating device on adapter 0 (AMD Radeon RX 6900 XT)
2022-06-23 18:49:20.738276: I tensorflow/c/logging.cc:34] Successfully opened dynamic library Kernel32.dll
2022-06-23 18:49:20.739402: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-06-23 18:49:20.739469: W tensorflow/core/common_runtime/pluggable_device/pluggable_device_bfc_allocator.cc:28] Overriding allow_growth setting because force_memory_growth was requested by the device.
2022-06-23 18:49:20.739734: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/device:GPU:0 with 14636 MB memory) -> physical PluggableDevice (device: 0, name: DML, pci bus id: <undefined>)
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 16333154288072444646
xla_global_id: -1
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 15346960384
locality {
bus_id: 1
}
incarnation: 13616500749135176656
physical_device_desc: "device: 0, name: DML, pci bus id: <undefined>"
xla_global_id: -1
]
性能検証
次の環境で簡単なMobileNetベースの画像分類モデルのトレーニングをCPUで実行したときとDMLでGPUを使ったときを比較し、DirectML利用による高速化を検証しました。
- OS: Windows10 Home(21H2)
- CPU: Ryzen5 5600X(6C12T)
- MB: msi mpg B550 gaming plus
- RAM: 3200MHz 16GBx2
- GPU: RX6900XT
検証に使ったのはTensorFlowの次のチュートリアルのコードを少し改変したもの。一応末尾に貼っておきます。
ただ、そのままコードを実行しようとするとData Augmentation の部分でエラーが出てしまったので、そこだけコメントアウトしています。
どうやらrandom_flip内で使われているオペレーションの一部が上手く動かない模様。まだプレビューなので致し方なしか。
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a device for operation Func/model/sequential/random_flip/map/while/cond/_0/input/_43: Could not satisfy explicit device specification '/job:localhost/replica:0/task:0/device:GPU:0' because no supported kernel for GPU devices is available.
で、Augmentationだけコメントアウトしてしまえば特に何事もなく動いてくれましたので、1エポックあたりの時間を見てみると、CPUが約43秒に対し、RX6900XT(DirectML)では約4秒と、10倍近い高速化を確認できました!
CPU
Epoch 1/10 63/63 [==============================] - 47s 713ms/step - loss: 0.2533 - accuracy: 0.8935 - val_loss: 0.0814 - val_accuracy: 0.9691 Epoch 2/10 63/63 [==============================] - 43s 675ms/step - loss: 0.1681 - accuracy: 0.9320 - val_loss: 0.0541 - val_accuracy: 0.9802 .... Epoch 10/10 63/63 [==============================] - 43s 679ms/step - loss: 0.0794 - accuracy: 0.9690 - val_loss: 0.0448 - val_accuracy: 0.9851
Epoch 1/10 63/63 [==============================] - 9s 76ms/step - loss: 0.1371 - accuracy: 0.9420 - val_loss: 0.0685 - val_accuracy: 0.9728 Epoch 2/10 63/63 [==============================] - 4s 55ms/step - loss: 0.0429 - accuracy: 0.9830 - val_loss: 0.1365 - val_accuracy: 0.9567 …… Epoch 10/10 63/63 [==============================] - 4s 56ms/step - loss: 0.0171 - accuracy: 0.9940 - val_loss: 0.1299 - val_accuracy: 0.9629
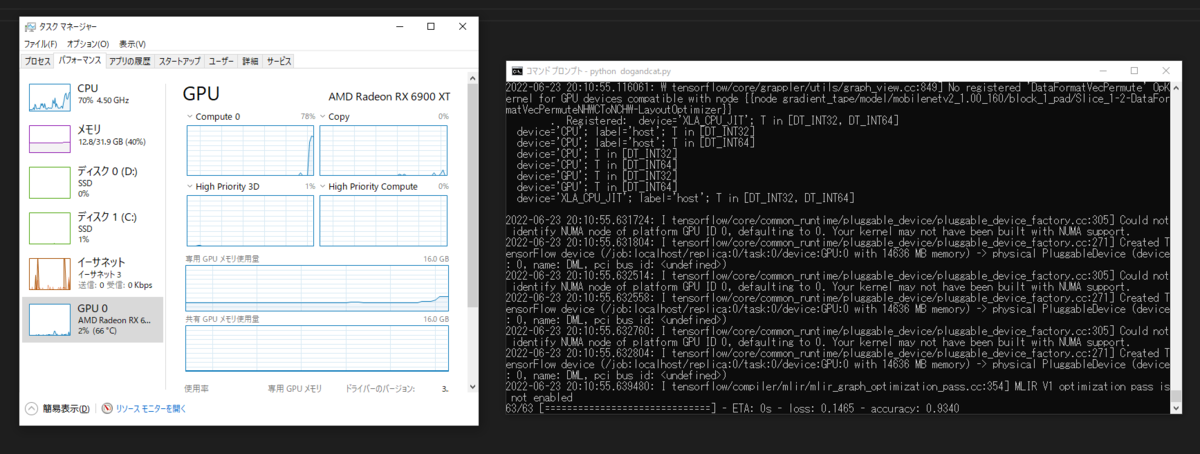
ついでに学習中のタスクマネージャを見てみると、GPU使用率やVRAM使用率が上昇していることが確認できました。
おまけのベンチマークに使用したコード。tf.device()の指定でCPUとGPUを明示的に切り替えています。
# Froked from https://github.com/tensorflow/docs-l10n/blob/master/site/ja/tutorials/images/transfer_learning.ipynb import os import tensorflow as tf from tensorflow.keras.preprocessing import image_dataset_from_directory _URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True) PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered') train_dir = os.path.join(PATH, 'train') validation_dir = os.path.join(PATH, 'validation') BATCH_SIZE = 32 IMG_SIZE = (160, 160) DEVICE = '/CPU:0' with tf.device(DEVICE): train_dataset = image_dataset_from_directory(train_dir, shuffle=True, batch_size=BATCH_SIZE, image_size=IMG_SIZE) validation_dataset = image_dataset_from_directory(validation_dir, shuffle=True, batch_size=BATCH_SIZE, image_size=IMG_SIZE) val_batches = tf.data.experimental.cardinality(validation_dataset) test_dataset = validation_dataset.take(val_batches // 5) validation_dataset = validation_dataset.skip(val_batches // 5) AUTOTUNE = tf.data.AUTOTUNE train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE) validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE) test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE) # data_augmentation = tf.keras.Sequential([ # tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'), # # tf.keras.layers.experimental.preprocessing.RandomRotation(0.2), # ]) preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input # Create the base model from the pre-trained model MobileNet V2 IMG_SHAPE = IMG_SIZE + (3,) base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE, include_top=False, weights='imagenet') image_batch, label_batch = next(iter(train_dataset)) feature_batch = base_model(image_batch) print(feature_batch.shape) base_model.trainable = True # Let's take a look at the base model architecture base_model.summary() global_average_layer = tf.keras.layers.GlobalAveragePooling2D() feature_batch_average = global_average_layer(feature_batch) print(feature_batch_average.shape) prediction_layer = tf.keras.layers.Dense(1) prediction_batch = prediction_layer(feature_batch_average) print(prediction_batch.shape) inputs = tf.keras.Input(shape=(160, 160, 3)) # x = data_augmentation(inputs) x = preprocess_input(inputs) x = base_model(x, training=False) x = global_average_layer(x) x = tf.keras.layers.Dropout(0.2)(x) outputs = prediction_layer(x) model = tf.keras.Model(inputs, outputs) base_learning_rate = 0.0001 model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate), loss=tf.keras.losses.BinaryCrossentropy(from_logits=True), metrics=['accuracy']) model.summary() history = model.fit(train_dataset, epochs=10, validation_data=validation_dataset)