概要
ほぼタイトル通り。PyTorchのDataLoaderではnum_workersを指定したときの並列化のために、裏側でmultiprocessingを使っていることが原因のようです。
Windowsにおいてmultiprocessingはif __name__=="__main__"ブロックの中で実行されることが想定されているため、Jupyterのセル中でmultiprocessingの子プロセスをSpawnしようとするとエラーが出ます。
で、このエラーは子プロセスの方で発生しているためか、Jupyterの方ではエラーが出現せずずっとセル横の表示が*のままとなり、あたかも実行中のように思えてしまうという挙動を示すようです。

VSCodeのJupyter実行環境をよく使っているのですが、これではJupyterカーネルのエラーを見ることができないため、てっきり自分のコード起因でハングしているものと考えてしまい小一時間苦闘してしまいました。
結局、Dataloaderのnum_workersをデフォルトの0にしたところ問題なくコードが動くことに気づき、同様の現象が普通のmultiprocessingをJupyter上で実行しようとしたときに起こったことを思い出してようやく原因究明。
あとから気づいたのですがこの内容はPyTorchの公式ドキュメントにも記載があるので、ちゃんと読んでおけばよかったという話でした。
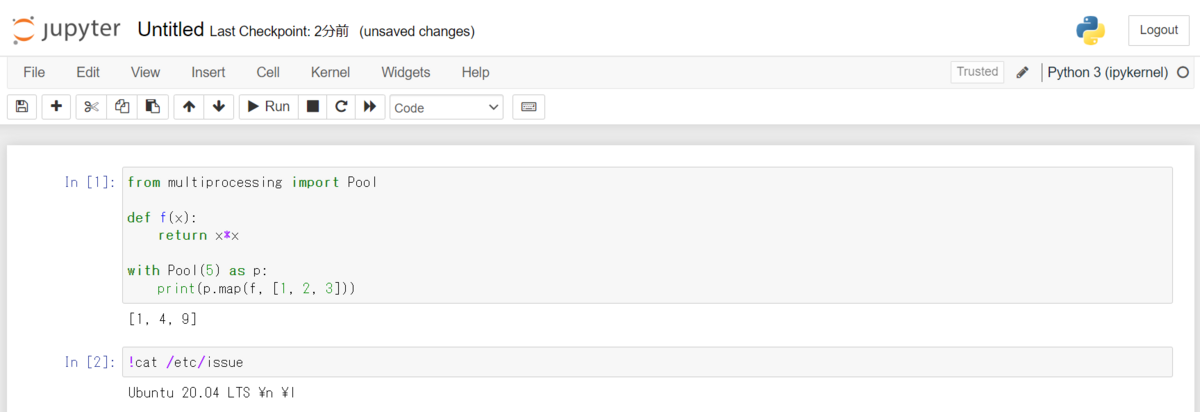
ここで書かれているように、LinuxとWindowsでは子プロセスの発生方法が違うためか、Linuxで動いているJupyterカーネルではこのような現象は起こりません。
解決方法
- とりあえず
num_workers=0にしてしまう - Jupyterで書くのを諦めて、.pyファイルにしてDataLoaderを
if __name__=="__main__:ブロック内に入れてしまう - Linux使う
解説?
合っているかどうかは保証しない解説。
multiprocessingの公式ドキュメントに書かれている説明によると、
Windowsで使われるプロセス生成方法のspawn()の説明:
親プロセスは新たに Python インタープリタープロセスを開始します。子プロセスはプロセスオブジェクトの run() メソッドの実行に必要なリソースのみ継承します。特に、親プロセスからの不要なファイル記述子とハンドルは継承されません。
「ワーカープロセスのプールを使用」にかかれている注釈:
注釈 このパッケージに含まれる機能を使用するためには、子プロセスから main モジュールをインポートできる必要があります。このことについては プログラミングガイドライン で触れていますが、ここであらためて強調しておきます。なぜかというと、いくつかのサンプルコード、例えば multiprocessing.pool.Pool のサンプルはインタラクティブシェル上では動作しないからです
とのことです。インタラクティブシェルで名前空間がどう管理されているのかは知らないですが、何れにせよ、spawn()で生成された子プロセスからは、Jupyterのセルで定義したfunctionを参照することができないようです。
一方、Linuxのデフォルトであるfork()では
親プロセスは os.fork() を使用して Python インタープリターをフォークします。子プロセスはそれが開始されるとき、事実上親プロセスと同一になります。親プロセスのリソースはすべて子プロセスに継承されます。
だそうですので、これであれば定義したfunctionが子プロセスからも見えることになり、正常に動作すると考えられます。
ちなみに、同様の現象はPyTorchに限らず、上記の例のように普通に自分の書いたコード内でmultiprocessingを使おうとしたときにも起こります。WindowsのJupyterで処理を並列化したいときは、joblibを使うと動くのでこちらを使うのがおすすめです。

import joblib
def f(x):
return x*x
joblib.Parallel(n_jobs=-1)(joblib.delayed(f)(i) for i in [1,2,3])