概要
家は広くなったものの買うものが無くなってきた30歳独身オタクとして、とうとう来るところまで来てしまった感のある買い物。
ここ1年くらいで友人に連れられて若干パチを打っていたのですが、球がランダムに跳ねながらヘソに入る様子を眺めつつ、たまに視覚・聴覚・触覚に強烈に訴えかける刺激が加えられ、うまくいけばお金が増える、という単純ながら人間の射幸心を巧妙に操作するその仕組みは確かに「面白い」。どちらかというと薬物とかに近い面白さな気がするが、良いように言うと頭が空っぽになり中々チルな感じとも言えなくもない。
ただ、10回ほど打って思ったのが、とにかく今の台は荒いし釘もキツ過ぎて楽しいよりもストレスのほうがデカい。最終的な収支は本当にトントンくらいだったが半日打つと収支はほとんど±50K以上で、40000発勝ちに脳を焼かれたかと思ったらその後-50Kが3連続続くとか、こんなものを続けていたら頭がおかしくなってしまう。
ということでホールで打つのは一旦引退し、ストレスを排し頭を空っぽにする機械として実機を家においてみることにしたお話。
おまけにデータカウンターがマイコンボードで自作できるという記事があったので、うちに転がっていたArduino Leonardoを使って自作してみることにした話も付け加えておく
まとめ
- 買った台は次の2台
- パチンコ: CR聖戦士ダンバイン256ver: 44,000円@メルカリ
- 家庭用電源、循環加工済み。別途パチンコを固定するためのこんな台も買った。
- スロット: パチスロマクロスデルタ: 37,262円@A-slot
- 家庭用電源、コイン不要機付き
- パチンコ: CR聖戦士ダンバイン256ver: 44,000円@メルカリ
- 実機を置く台としては段ボール製のシンプルスタンドを購入
- 重さ的に一人で設置できるのか大分不安だったが、163cm/50kgチビガリの自分でもなんとか設置できた。
- スロットは何とか自力で持ち上がったのでそんなに設置には苦戦せず。パチンコのほうが大分重いので手こずったが、倒した状態で片側を持ち上げるとかしながら気合で対処した。可能なら友人を召喚しましょう。
- 自作カウンターはArduinoとブレッドボード、抵抗数個があれば簡単に作れる
- 外部集中端子というIN/OUTや当たりの情報を出力する基板がついているので、そこから得られる信号を受け取るような仕組み
- パチンコのほうはまだ信号の受け取り方がわかっておらずカウンターを作れていない
- pyserialでArduinoから情報を受け取りSQLiteに保存し、Flaskでウェブアプリとして表示するような仕組みを作成することで、タブレットから台のデータを見れるようにした
- 外部集中端子というIN/OUTや当たりの情報を出力する基板がついているので、そこから得られる信号を受け取るような仕組み
いずれにせよ、ゲーム機が平気で7万とかする時代にこれだけデカくてちゃんとした遊技機が3万とかで買えるのはお得感がある。理解のある人しか家に入れられないようにはなるが、それを厭わない人なら1台くらい持っててもいいのかも。
設置例

台の選定、購入時の懸念点について
既に友人が家パチを導入しており台によるが3万代から買えると聞いていたので、1日の負け額より少ないじゃん!みたいな考えで安めの台からパチ・スロ1台ずつを買うことにした。どうせ今年の8月に邪神ちゃんのスロが出る予定でこれの実機はいつか買うつもりなので、その予行練習も兼ねている。
パチンコのほうは好きな作品であるダンバインの台を買うことにした。すでにホールに存在しないが妙に評判のいい1を打ってみたかったのもあり、メルカリで役物も動作する256ver.が出ていたので送料込み44,000円で購入。古い台ということもありあまり綺麗ではなかったが、軽く清掃したうえでとりあえず無事に動いている。
スロットのほうはA-slotでGWセールをやっていたので安い台で知っている版権のものを買うことにした。定番として北斗・エヴァ・まどマギも考えたが、あえて普通には打たなさそうなマイナー目なマクロスデルタを選択。送料、コイン不要機込みとGWセールのおまけで段ボールスタンドもついて37,262円で購入できた。こちらは専門店の品ということもあり非常に状態が良く、清掃も必要なかった。
で、未経験の状態からいざ実機を買うとなるといくつか不安となる点があった。ということで購入前に考えていたことと、実際に買ってみてどうだったかをまとめておく。
- 台の重さはどれくらいなのか?一人で設置できるのか?
- 公式サイトなどで重さが公開されていることはあまりないが、ネットで調べるとパチンコは40kg前後、スロットは30kg前後のものが多いようだった。
- 163cm/50kgのチビガリの自分でもなんとか設置できたので、普通の成人男性なら問題なく設置できると思う。理解のある友人がいるなら呼んだほうがいいだろう。
- 家パチ・家スロ用語: 家庭用電源?循環加工?役物停止?コイン不要機?音量調整?
- パチの場合: 家庭用電源、循環加工、音量調整が必須オプション。役物停止加工はお好みで。
- スロの場合: 家庭用電源、音量調整が必須オプション。コイン不要機は無くてもメダルがあれば遊べるのかもしれないが、音や管理の面倒さを考えるとこれも必須級のオプションだと思う。
- スマスロの場合は別途ユニットが必要らしいので注意。
- 騒音問題
- パチもスロも音楽やSEは調整可能なので意外と気にならない(駆動音以下にできるという意味で、音量MAXとかにするなら別)。それより問題は駆動音
- パチンコのほうは役物が動くときの音、球の打ち出し音が結構大きい。
- スロットのほうはそこまで気にならないが、リールの回転はそれなりに振動がある。メダルを使う場合はさらに煩いと思うので、音を気にする場合はコイン不要機は必須だと思う。
- 一応振動防止のカーペットを敷いてみたが、どれだけ下に響いているかはわからない。今のところ苦情が来たことはないが、とりあえず20時以降に打つのは控えている。
- 2階以上に住んでいる人は良く考えて買ったほうがいいと思う。
- パチもスロも音楽やSEは調整可能なので意外と気にならない(駆動音以下にできるという意味で、音量MAXとかにするなら別)。それより問題は駆動音
- 必要な付属品
- 上記の筐体加工以外にも、必要に応じて実機を置くためのスタンドや、パチンコ台を固定する台も必要。
- スタンドは段ボール製のものが5,000円程度で売っている。耐荷重は100kg以上あるので、パチンコ・スロット両方とも問題なく置けると思う。
- パチンコ台の固定台は中古で買う場合ついていることもあると思うが、ない場合は別途買う必要がある。適当な木製板で自作してもいいかもしれないが、専用のものも売っている
- パチンコの場合循環加工をしていても数十発分の球は必要。これも多分中古で買う場合はついてくると思うが、ない場合は別途買う必要がある。
- 台を開けるための流通鍵はついてきていることが多いと思う。
とりあえず買う分には結構気楽に買えるが、買ったもののまともに稼働できるかは環境次第だと思う。最初からガチな金属ラックやデータカウンターなどの周辺機器を揃えると意外な制限にぶち当たり処分が大変になる可能性もあるので、まずは簡易スタンドと安い台を買ってみて、環境的に問題なさそうなら周辺機器を揃えていくのがいいと思う。
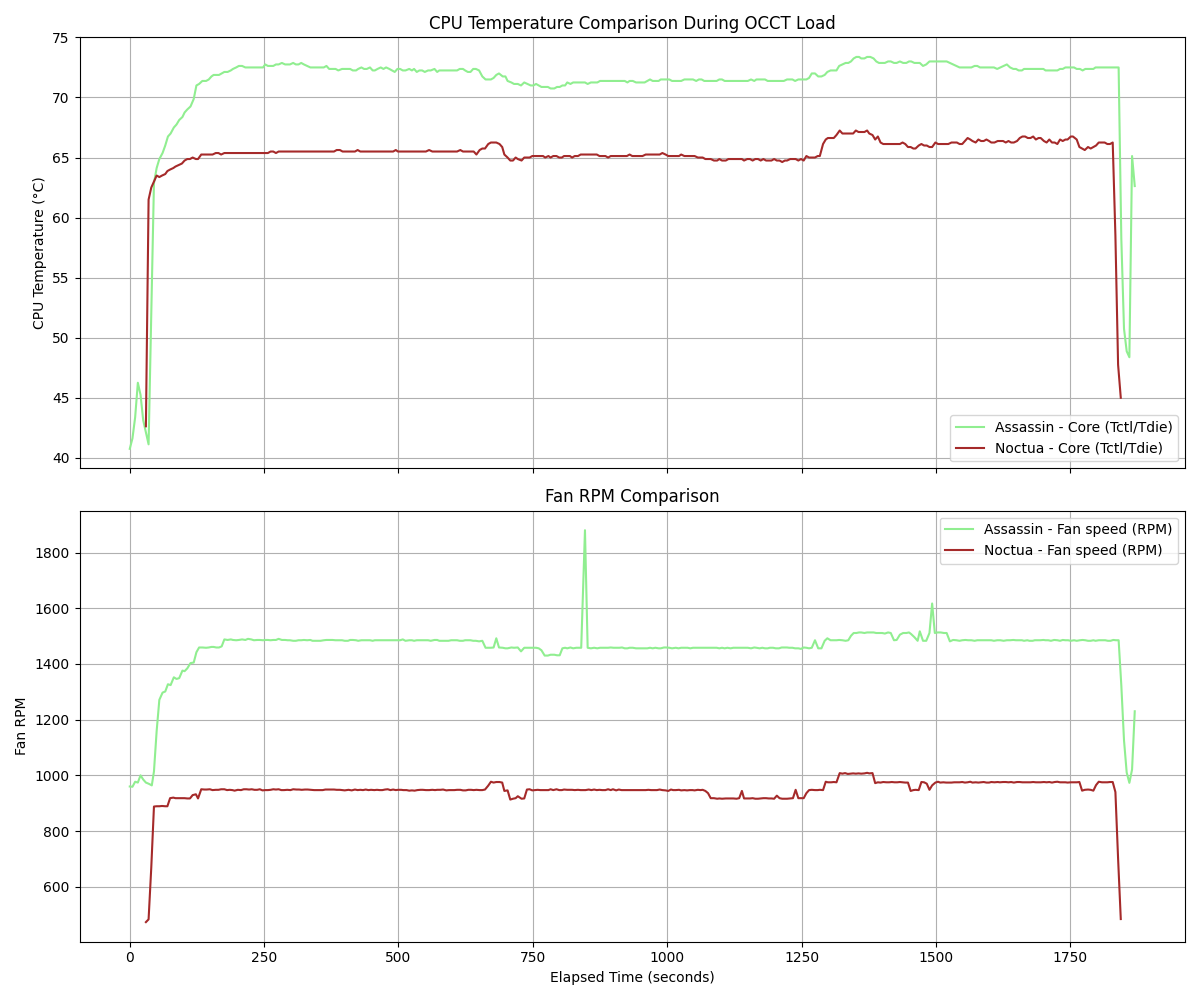
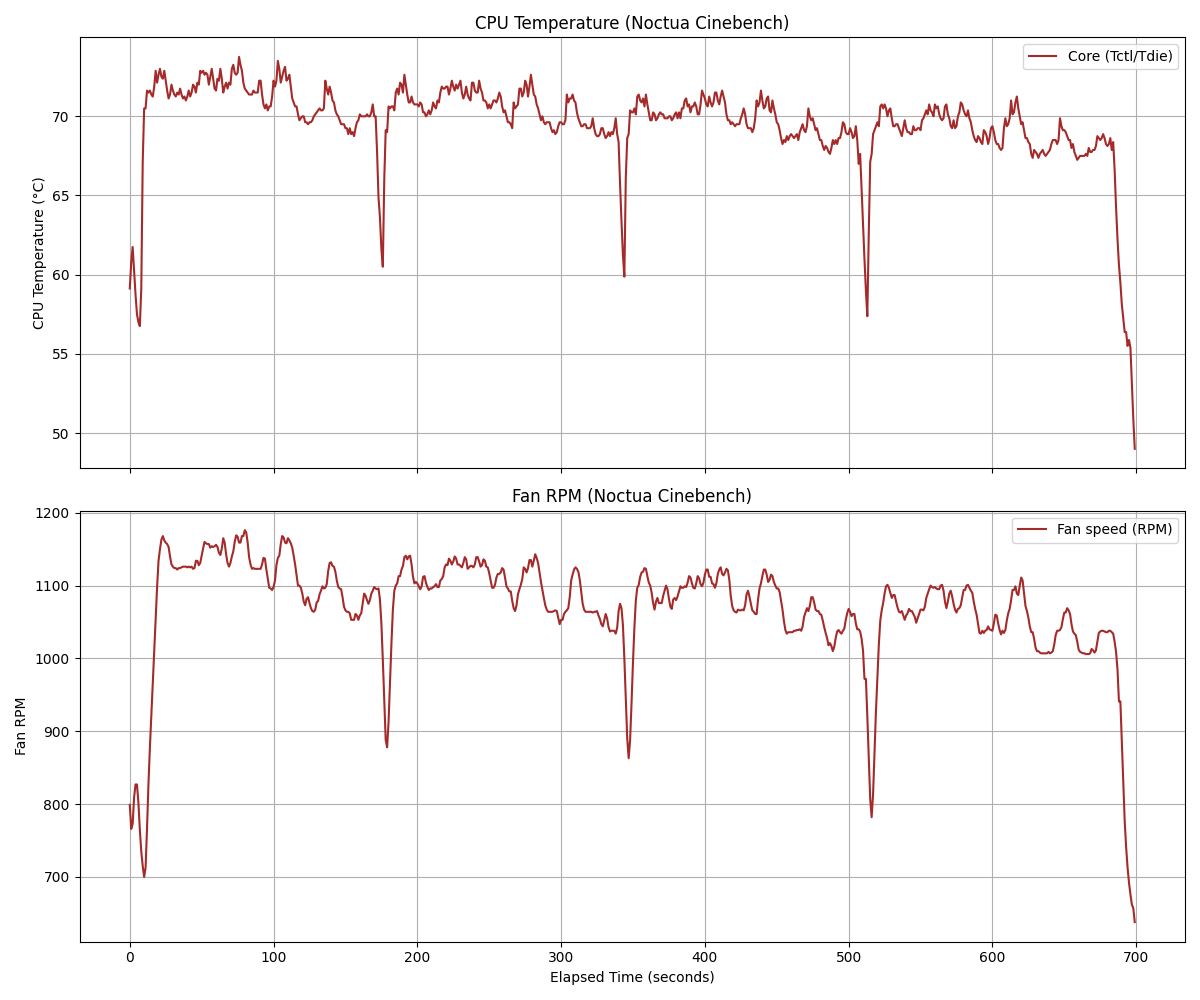
データカウンターの自作
このサイトを大いに参考にさせていただいたが、スロットのデータ出力は単純なリレーのON/OFF信号なので、電圧をかけた上でArduinoのデジタルピンで受け取るような仕組みを作れば簡単にカウンターが作れるらしい。
家にLeonardが余って転がっていたのでこいつを使うこととし、動作確認として次のようなコードでシグナルをカウントすることができると思う。
// --- ピン割り当て (Leonardoの割り込み対応ピンを使用) --- const int PIN_IN = 0; // 外部集中端子の1番 const int PIN_OUT = 1; // 外部集中端子の2番 const int PIN_RB = 2; // 外部集中端子の3番 const int PIN_BB = 3; // 外部集中端子の4番 // --- カウンタ変数 (割り込み内で変更するため volatile を指定) --- volatile unsigned int count_IN = 0; volatile unsigned int count_OUT = 0; volatile unsigned int count_RB = 0; volatile unsigned int count_BB = 0; // --- チャタリング防止用の時間記録変数 --- volatile unsigned long last_time_IN = 0; volatile unsigned long last_time_OUT = 0; volatile unsigned long last_time_RB = 0; volatile unsigned long last_time_BB = 0; const unsigned long DEBOUNCE_DELAY = 50; // チャタリング防止時間(ミリ秒)。実機に合わせて調整 // --- データ送信用のフラグ --- volatile bool data_updated = false; // ========================================== // 割り込み処理関数 (ISR) // ※割り込み処理内ではSerial.printなどは使わず、最小限の処理にする // ========================================== void isr_IN() { unsigned long current_time = millis(); if (current_time - last_time_IN > DEBOUNCE_DELAY) { count_IN++; last_time_IN = current_time; data_updated = true; } } void isr_OUT() { unsigned long current_time = millis(); if (current_time - last_time_OUT > DEBOUNCE_DELAY) { count_OUT++; last_time_OUT = current_time; data_updated = true; } } void isr_RB() { unsigned long current_time = millis(); if (current_time - last_time_RB > DEBOUNCE_DELAY) { count_RB++; last_time_RB = current_time; data_updated = true; } } void isr_BB() { unsigned long current_time = millis(); if (current_time - last_time_BB > DEBOUNCE_DELAY) { count_BB++; last_time_BB = current_time; data_updated = true; } } // ========================================== // 初期設定 // ========================================== void setup() { // シリアル通信の初期化 Serial.begin(9600); // 【重要】Leonardo特有の処理:USBシリアル接続が確立するまで待機 while (!Serial) { ; // シリアルモニタが開かれるまで待つ } Serial.println("System Start!"); // ピンのモード設定 // 外部プルアップ回路がある場合は INPUT、無い場合は INPUT_PULLUP にしてください pinMode(PIN_IN, INPUT); pinMode(PIN_OUT, INPUT); pinMode(PIN_RB, INPUT); pinMode(PIN_BB, INPUT); // 外部割り込みの設定 (High -> Low に落ちた瞬間に反応 = FALLING) attachInterrupt(digitalPinToInterrupt(PIN_IN), isr_IN, FALLING); attachInterrupt(digitalPinToInterrupt(PIN_OUT), isr_OUT, FALLING); attachInterrupt(digitalPinToInterrupt(PIN_RB), isr_RB, FALLING); attachInterrupt(digitalPinToInterrupt(PIN_BB), isr_BB, FALLING); } // ========================================== // メインループ // ========================================== void loop() { // データが更新された場合のみシリアル通信でPCへ送信 if (data_updated) { // データの読み取り中に割り込みが入って値が狂うのを防ぐため、一時的に割り込みを停止 noInterrupts(); unsigned int current_IN = count_IN; unsigned int current_OUT = count_OUT; unsigned int current_RB = count_RB; unsigned int current_BB = count_BB; data_updated = false; interrupts(); // 割り込み再開 // PCへデータを送信 (カンマ区切りなどで送信するとPC側で処理しやすいです) Serial.print("IN:"); Serial.print(current_IN); Serial.print("\tOUT:"); Serial.print(current_OUT); Serial.print("\tRB:"); Serial.print(current_RB); Serial.print("\tBB:"); Serial.println(current_BB); } }
これが問題なく動けば、あとはIN/OUT、RB/BBの信号を受け取りSQLiteに保存するような仕組みを作り、FlaskでデータをフェッチするAPIを生やし、フロントエンドでデータを表示するような仕組みを作れば完成。適当に次のようなプロンプトでGemini Proにコードを生成させてみたが、ほぼ一発で動くものが出来た。
# 1回目 Arduino から情報を受け取って、データを保存・表示するためのPythonベースのウェブアプリを作成したいと思います。Arduinoはシリアル通信でデータを送信する前提とし、Python側ではpyserialを使ってデータを受け取ります。受け取ったデータはSQLiteに保存し、Flaskを使ってウェブアプリとして表示するような仕組みを作りたいと思います。 # 2回目 機械割、BB/RB確率、スランプグラフを実装したいと思います。現在のコードをベースとして変更案を提示してください
今のところ長いAT中にBBのカウントが若干おかしくなる問題があるが、これは機種特有の仕様かもしれないので、もう少しデータを取ってみてから対処するか考えることにする。どうせ設定は自分で入れているので、差枚が分かれば十分使える感じ。


また、パチンコのほうはまだ信号の受け取り方がわかっていないので、こちらはまだ未着手となっている。
おまけ: 台の感想
- ダンバイン256ver
- やはりチャージなしで256で図柄揃い、当たれば時短 or LTなしでそこそこやれるラッシュというのはシンプルで良い。
- 左打ちはカスタムなどないので当たらない演出を見続けることになるが、釘をガン開けしているのでそこまでストレスは感じない。
- 今のところ最初に打った時に数回転で入ったラッシュが50連くらいしたのが最高で、あとは大した当たりはない。やれるスペックな気がするが現実は厳しい。
- マクロスデルタ
- スロットのほうは全然打ったことがなかったので新鮮な気持ちでプレイ中。パチンコの先バレをひたすら見続けるようなゲームと思うと中々楽しめている
- 設定6だとかなりの割合でATに入るが上乗せがショボく完走する未来が見えず、負ける気はしないが大勝もしなさそう。設定5にしてみたが今のところCZスルーを3連で引いていたりするので店じゃなくて良かった。低設定だとどれだけヤバいのか、実戦する予定の8月の邪神ちゃんスロに向けて今から戦々恐々である。
- ただ、演出がちょっと残念で折角のマクロスなのにATに入らないとほぼワルキューレの曲を聴くことができない。しかも収録されているのが1番だけ。CZ移行前で風の歌を聴いている時間のほうが長いのでは?


















{kind=link}