まえがき
2025/3/15(土)、滅多に週末外に出ることがない私は珍しく大阪・難波に遠征していた。舞台版邪神ちゃんを見に行くためである。
せっかく難波に行くのであればということで、ほとんど期待はせずにRTX5090を探しながらPCパーツ屋を巡っていた。
RX9070やRTX5080は普通に在庫している店舗があり、ちょっとは流通改善しているんだなーなどと思いながらもRTX5090はない。流石にあるわけないと思っていたのだが、ジョーシンに2枚のRTX5090、MSIのVANGUARDとSUPRIM LIQUIDが売られているではないか!価格は前者が52万、後者は58万円とMSIの希望小売価格であった。
とはいえ、RTX4090を持っているのもあり、Ada世代の性能の向上を考えると出せて45万までかな……と思っていたので、一旦グッと堪えて他のショップを巡ることに。
RTX5090のほかにもASUSから最近発売されたStrix Halo搭載タブレットのGZ302EAの実機展示(ジョーシンにあった)を見てみたり、RTX5090を買うことになったら必要になるATX3.1電源を物色してみたり、1時間ほど日本橋をぶらぶらとしていた。
そのときもずっとRTX5090を買うか買うまいか、ドル円の動向、トランプリスク、そろそろ在庫が増えてくる可能性、間もなく始まるGTC、買ったとしてRTX4090をどうするか、本当にMSIでいいのか、間もなく30になる独身男がこんなフリーダムにお金を使ってて大丈夫なのか、いっそのこともう売れててくれないかな、などなど苦しい脳内会議が繰り広げられていたのだが、いざジョーシンに戻ってみるとまだそこには2枚のRTX5090が鎮座していた。
冷静に考えれば待つべきと思っていたものの、やはり見てしまうと欲しくなる。店内を数分回りながら三度GPUコーナーを通り過ぎたとき、理性を欲望が上回り、私は財布を取り出しながら店員さんにこれくださいと言ってしまったのであった。……「ある」のがいけない!「ある」のがいけない!
空冷派なので52万のMSI RTX5090 VANGUARD LAUNCH EDITIONを選択。
早く買わないと高くなる・いつまでも買えない雰囲気に煽られて値段に見合わないものを買う資本主義的ゲームに参加してしまうのは悔しいが、結局買えるときに買うのが正解かと自分を納得させる。
値段が高いのはMSIが仕切値を上げているため、それも元をたどればNVIDIAのチップやGDDR7の値段が高いのが原因であるそうなので、とりあえず定価で通常販売してくれたジョーシンには感謝しかありません。
更に、せっかく買ったRTX5090が燃えてしまっても困るので、ケーブルに温度センサーがついているらしいATX3.1電源であるAsrock PG-1300G(44,000円)も合わせて買った。
非常に高い買い物になったものの、買ってしまったものは有効活用していくしかない。だいぶ思うところが多い買い物であったため前置きが長くなったが、とりあえずいつもやっているゲーム系のベンチマークと、機械学習のトレーニング・インファレンス性能をViT、GPT2、Gemma3モデルで測定してみた。
まとめ
- 新しいモデルであるMSI VANGUARDであるが、ちゃんと600W近い消費電力にも静かに対応できるよいクーラーだと思う。ただ高い。
- ゲーム系のベンチマークではすでに各所で報告されているように、RTX4090比で大体10~40%程度の性能向上が見られる。
- 明確に性能は上がっているのだが、現状RTX5090がないと満足にプレイできないゲームは存在しないと思うので、もはやゲーム用に買うものではない気もする。
- 機械学習系のベンチマークでも大体10~40%程度の性能向上が見られている。
- 価格性能比を考えると、やはりRTX5090は45万くらいまでが適正価格かな……というのが正直な感想
- とはいえ、VRAMが32GBあるというのは代えがたいメリットなので、機械学習用であれば持ってて損はないのは間違いない。
総評としては、NVIDIAのMSRPで買えない限りは、RTX4090からの買い替えはコスパが悪いとはっきり言って良いと思う。サプライズは無く、各種サイトでベンチが取られている通りの性能である。それに勝る理由(マルチフレーム生成による超高FPSでゲームしたい、32GBのVRAMが欲しい)があれば、今後ハイエンドGPUの行く末がどうなるのか全くわかりませんし、買えるときに買うしかないですね。
ギャラリー
MSI VANGUARDはVENTUS、GAMINGと最高位のSUPRIMの間に位置するグレードの、空冷のハイクラスモデルとのこと(MSIのラインナップの説明はこの記事がわかりやすい)。基本的にOC性能は求めず価格とチップの種類重視で、値段の高いカスタムクーラーのGPUを買うことはない自分にとって初めての高級なモデルでもある。 さすがに52万もするだけあって、箱の豪華さが段違いである。ジッパーを引っ張って外装を開けるギミック付き。


今回買ったのはLaunch Editionという初回限定版みたいなやつで、MSIのマスコットであるLucky君のランダムフィギュアが同梱されている。シークレットもあるらしいが、私はHollywood Lucky君がついてきました。しかし、52万もするグラボのおまけに対して"...collect them all."とは冗談も大概にしてほしい。


形状は直方体で重さも相まってレンガのようである。



今まで使っていたRTX4090(ZOTAC TRINITY OC)と比べると、思ったほど大きさに差がないが重さがだいぶ違う(1.96kg vs 2.41kg)。身近なものと比較すると2Lペットボトルよりもデカく重いのだが、これは果たしてマザボに刺していいものなのだろうか。


もともと電源としてはCoolerMaster MWE GOLD 1250 V2を持っていたのだが、あいにくATX3.0の電源であるため、万全を期すため(万が一故障したときにケチをつけられて保証受けられないみたいなことにならないように)、ATX3.1規格かつ12V-2x6コネクタに温度センサーがついていて加熱時に電源供給を遮断する機能を搭載したAsrockのPG-1300Gを購入した。 ちょうど日本橋のパソコン工房に在庫があったため店頭購入したのだが、Steel LegendマウスパッドとTaichi Tシャツがおまけでついてきた。
ちなみに、非常にCPU12Vケーブルが細くて取り回しが良かったです。

環境
今回GPU換装のついでに、セールで買っておいたがめんどくさくて放置していた4TBのSSDに換装し、OSの再インストールも実施してクリーンな環境で測定を行った。
価格は購入当時のものですが、CPUとかはもうちょい安いタイミングもあったと思います
- PCケース:Fractal Design Torrent ¥30,800
- 電源: Asrock PG-1300G ¥44,800
- マザーボード: MSI X670-P WIFI ¥29,776
- メモリ: Micron 4800MHz 2x32GB ¥25,980
- CPU: Ryzen9 7950X3D ¥111,800
- GPU: MSI RTX5090 VANGUARD SOC ¥519,800 or ZOTAC RTX4090 Trinity OC ¥301,020
- SSD: WD BLACK 850X ¥39,435
- CPUクーラー: DeepCool Assassin IV ¥15,000
- OS: Windows 11 Pro ¥24,000
CPU、メモリが世代遅れになってしまったが、現行ハイエンドのコンシューマ?向けPCであると思う。合計金額は占めて¥841,391と、いよいよ中古車も多少種類を選びながら買えるくらいの金額になりました。冗談じゃないですね。
BTOだとRTX5090搭載マシンが駿河屋ですら95万とかするらしいので、このクラスになると自作したほうがBTOよりも安くなりそう。新しいCPUでもう少し良いマザボ・メモリとか選んだらあんま変わらないか?とも思いますが、このクラスのマシンを必要とする人はそれぞれこだわりポイントがあると思うので、調整が利く自作やフルカスタムの価値はあると思います。
(2025/3/26 追記) ツクモのG-GEARで9950X3D搭載モデルも税込み85万とのことなので、これであればBTOで買ってもいいかもしれませんね。
【TSUKUMO】G-GEAR、NVIDIA GeForce RTX 5090を搭載したゲーミングPCの新モデルを発売 - 【TSUKUMO(ツクモ)】プレスリリース
また、今回RTX5090に換装したところ、なぜか2枚目、3枚目のM.2 SSDが認識しなくなってしまった。MSI X670-P WIFIは安かったので買ったのだが、USBも不安定だし割と似たようなM.2・USB周りの不具合がほかの人からも報告されているようで、あんまり良い板じゃなかったですね。Zen6発売までは持たせたいが……。
本当はOptane 905P上にDual bootのUbuntu環境があったのだが、そのような事情からネイティブなLinux環境でのベンチマークはいったん棚上げとした。今回の機械学習系ベンチマークはWSL2上で実行したものです。
また、MSI VANGUARD のファン設定は”Silent"にしています。
CUDA12.8でのPyTorchインストールについて
RTX50シリーズではCUDA12.8以上が必要なため、現状のStable ReleaseのPyTorch(CUDA 12.6)をインストールしてもAssertionError: Torch not compiled with CUDA enabledが発生してしまう。
を見たところ、PyTorchのNightlyビルドにCUDA 12.8用のwhlがあるようである。
したがって、次のようなコマンドでNightly版のCUDA12.8対応PyTorchをインストールしました。
pip install --pre torch torchaudio torchvision --index-url https://download.pytorch.org/whl/nightly/cu128
また、機械学習系ベンチではTransformersリポジトリのExampleコードを使っていますが、これらはInstall from sourceでないと動かないので、
git clone https://github.com/huggingface/transformers.git cd transformers pip install .
でインストールする必要があります。
ベンチマーク
目次
- GPU-Z
- 3DMark
- FF14 黄金のレガシー
- MH Wilids
- 画像分類(
google/vit-base-patch16-224-in21k) - Language Modeling(
openai-community/gpt2) - LLM Inference(Gemma3-12b, 4b@bfloat16)
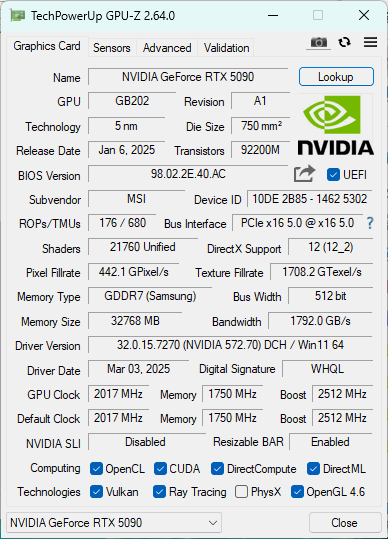
GPU-Z
GPU-Zを見てみましたが、噂のROP欠けはとりあえず無さそう。今世代のRTX5090の最大の特徴と思われる、GDDR7+豪勢な512bitメモリバスによる1792GB/sという超高速なVRAM転送帯域が目を引きます。
一つ気になるのが、PCIe5.0x16がないはずのX670なのに5.0でリンクしているっぽいことです。
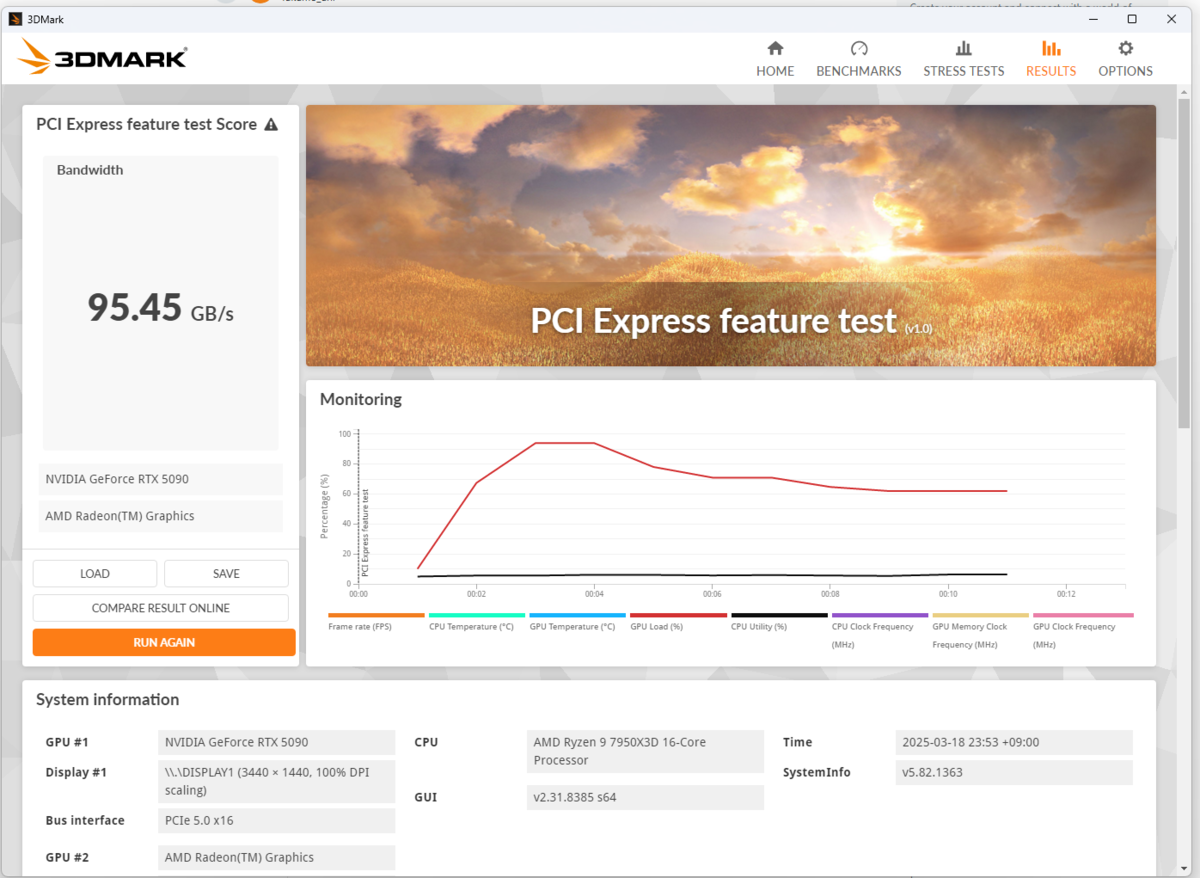
3DMark
すべてのベンチでちゃんと性能向上が見られています。特にGPU性能が重要となる新しく重めのベンチのほうが差が付きますね。
ベンチ中RTX5090が示した最高温度は65度程度でしたので、MSI VANGUARDの冷却性能も問題ないと思われます(部屋が寒かったのもあるかもしれませんが)。
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| Fire Strike Ultra | 24285 | 32291 | 1.330 |
| Time Spy Extreme | 17309 | 21768 | 1.258 |
| Port Royal | 25600 | 37404 | 1.461 |
| Steel Nomad Light | 43104 | 46932 | 1.089 |
| Steel Nomad | 9188 | 14070 | 1.532 |
また、PCIe5.0x16でリンクしている疑惑の確認のため、PCIe Feature Testも実施。96.37GB/sというPCIe4.0x16を超える速度が出ているので、本当にPCIe5.0x16でリンクしている?のかもしれません。やっぱこのマザボちょっとおかしい気もする。
FF14 黄金のレガシー
もうFF14ベンチは軽すぎてあまり測定する意味はないですが、最低FPSも平均FPSも着実に向上しているので、最高のエオルゼアライフを送りたければRTX5090を買ってもいいのではないでしょうか
- 3440x1440, 最高設定
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 28689 | 33245 | 1.160 |
| Min FPS | 88 | 92 | 1.045 |
| Ave FPS | 199.5 | 230.4 | 1.155 |
- 3840x2160, 最高設定
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 19353 | 25352 | 1.310 |
| Min FPS | 82 | 95 | 1.159 |
| Ave FPS | 136.4 | 173.5 | 1.271 |
MH Wilids
最近流行りのモンハンワイルズのベンチマークも実施。ちなみに私は笛使いです。
RTX50世代の特徴であるFrame GenerationをオンにするとRTX4090との差が開いているように見えます。そんなに高いFPSが必要なゲームではないですが(なんならFPSが高いと連続ヒット系の攻撃の判定が減ってダメージ減るとか聞いた気がする)、RTX5090があると4K最高画質でも144Hzのモニターを持て余さなくて済みそうです。
また、4時間くらい実際にウルトラ設定/3440x1440解像度でプレイしながら温度を見てみましたが、大体消費電力350W、ファンスピード30%、コア温度60度、メモリ温度65度くらいで安定していました。
- 3440x1440, 最高設定, レイトレ高, Frame Generation OFF
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 33436 | 35256 | 1.054 |
| Ave FPS | 98.75 | 103.58 | 1.048 |
- 3440x1440, 最高設定, レイトレ高, Frame Generation ON
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 26405 | 31804 | 1.204 |
| Ave FPS | 155.14 | 186.78 | 1.204 |
- 3840x2160, 最高設定, レイトレ高, Frame Generation OFF
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 28831 | 33495 | 1.162 |
| Ave FPS | 84.41 | 98.34 | 1.165 |
- 3840x2160, 最高設定, レイトレ高, Frame Generation ON
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| score | 20991 | 27372 | 1.304 |
| Ave FPS | 123.23 | 160.25 | 1.301 |
ViT
huggingface/transformersのExampleにあるrun_image_classification.pyを、次のコマンドで実行。
python run_image_classification.py \
--dataset_name beans \
--output_dir ./beans_outputs/ \
--remove_unused_columns False \
--label_column_name labels \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--eval_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
samples_per_secondで比較するとなぜかRTX4090のが速くなってしまった。かなりBatch Sizeを小さく実験をしてしまったので、性能差が見にくくなってしまったかも。実行中のGPU使用率は50%程度で、消費電力も300W程とあまりHWを使い切れていない感じでした。
RTX5090のみBS=128で実行してみましたが、若干処理速度が上がりましたね。
- RTX4090
***** train metrics ***** epoch = 5.0 total_flos = 373122447GF train_loss = 0.22 train_runtime = 0:00:46.43 train_samples_per_second = 111.328 train_steps_per_second = 13.997 ***** eval metrics ***** epoch = 5.0 eval_accuracy = 0.985 eval_loss = 0.0761 eval_runtime = 0:00:00.55 eval_samples_per_second = 239.898 eval_steps_per_second = 30.664
- RTX5090
***** train metrics ***** epoch = 5.0 total_flos = 373122447GF train_loss = 0.2201 train_runtime = 0:00:50.98 train_samples_per_second = 101.41 train_steps_per_second = 12.75 ***** eval metrics ***** epoch = 5.0 eval_accuracy = 0.9774 eval_loss = 0.0795 eval_runtime = 0:00:00.62 eval_samples_per_second = 212.545 eval_steps_per_second = 27.167
- RTX5090(BS=128)
***** train metrics ***** epoch = 5.0 total_flos = 373122447GF train_loss = 0.7684 train_runtime = 0:00:41.50 train_samples_per_second = 124.555 train_steps_per_second = 1.084 ***** eval metrics ***** epoch = 5.0 eval_accuracy = 0.9699 eval_loss = 0.5824 eval_runtime = 0:00:00.58 eval_samples_per_second = 228.145 eval_steps_per_second = 3.431
GPT2 Language Modeling
huggingface/transformersのExampleにあるrun_clm.pyを、次のコマンドで実行。
python run_clm.py \
--model_name_or_path openai-community/gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
このトレーニング中にはほぼずっとフルロードでGPUが稼働しており、消費電力は最大580Wに達していました。
学習中だんだん温度は上がる様子が見られ70度を超えることもありましたが、ファンスピード的にはだいぶ余裕があり、40%程度で70度安定という感じです。
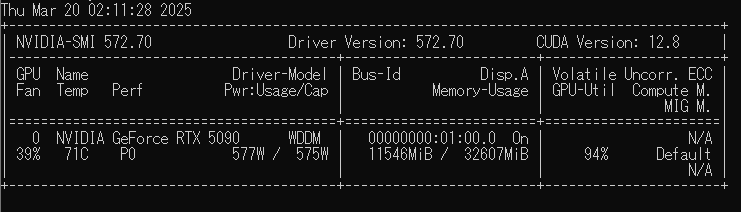
さすがに性能を発揮しきれるケースにおいては、RTX4090と比べて性能が大きく上がっていることが確認できました。
- RTX4090
***** train metrics ***** epoch = 3.0 total_flos = 3384472GF train_loss = 3.0904 train_runtime = 0:04:14.13 train_samples = 2318 train_samples_per_second = 27.363 train_steps_per_second = 6.847 ***** eval metrics ***** epoch = 3.0 eval_accuracy = 0.4274 eval_loss = 3.0433 eval_runtime = 0:00:02.81 eval_samples = 240 eval_samples_per_second = 85.321 eval_steps_per_second = 21.33 perplexity = 20.9749
- RTX5090
***** train metrics ***** epoch = 3.0 total_flos = 3384472GF train_loss = 3.0908 train_runtime = 0:03:05.92 train_samples = 2318 train_samples_per_second = 37.403 train_steps_per_second = 9.359 ***** eval metrics ***** epoch = 3.0 eval_accuracy = 0.4276 eval_loss = 3.0436 eval_runtime = 0:00:02.17 eval_samples = 240 eval_samples_per_second = 110.518 eval_steps_per_second = 27.63 perplexity = 20.98
LLM Inference(Gemma3-12b, 4b@bfloat16)
最後にGemma3を使った推論速度の検証を行いました。
google/gemma-3-12b-itに記載されているHuggingFaceを使った推論コードをもとに、蜂と花の画像に対する説明をさせた時の出力トークン数と推論時間を測定した結果を以下に示します。
{kind=link}
精度はbfloat16を使っています。出力サンプルは次のような感じで、大体100トークンくらいの文章が生成されていました。
Overall Impression: The image is a close-up shot of a vibrant garden scene, focusing on pink cosmos flowers and a busy bumblebee. The composition is natural and slightly blurred in the background, drawing attention to the central flower and insect. Main Elements: * Cosmos Flowers: The primary focus is on several pink cosmos flowers. They have delicate, slightly ruffled petals in varying shades of pink. The central flower
- Gemma3-12b-it
VRAMに収まらないサイズのモデルなので、RAMにも重みがロードされています。このあたり、メモリの帯域幅が広くなっていることもあるのか、RTX4090と比べてRTX5090の方が速い結果が出ました。とはいえ実用的な速度ではないので、量子化したモデルを使うべきでしょう。
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| モデルロード時間 | 19.05 | 13.94 | 0.732 |
| 生成時間 | 190.95 | 129.67 | 0.679 |
| 速度 | 0.52 | 0.77 | 1.48 |
- Gemma3-4b-it
こちらのモデルは24GBのVRAMでもモデルが乗り切るものです。RTX5090のGPU使用率も50%程度で性能が出し切れておらず、推論時間も短くてあまり差が出なかったようです。
| RTX4090 | RTX5090 | ratio | |
|---|---|---|---|
| モデルロード時間 | 6.03 | 5.50 | 0.912 |
| 生成時間 | 3.80 | 3.53 | 0.929 |
| 速度 | 26.33 | 28.29 | 1.074 |
おわりに
まだまだいろいろ検証したい内容はありますが、長くなりすぎたので一旦この辺で止めときます。
これからまたコンペやらなんやらで使って行くつもりなので、そこで性能検証できた内容があればまた新しい記事を書くかも。
しかし、RTX4090をどうしようかが悩みどころ。サブのEPYCマシンに載せれば普通に一線級の性能が出るのでそっちで使ってもいいのですが、さすがに資金を回収したい気持ちも強い。
ただ、売価が30万近くとなると最近特に治安が悪そうなメルカリで売るのは怖いし、下手すると確定申告も必要になりそうだし、かといって普通に買取依頼すると20万くらいにしかならないので悔しいし……。
買えて嬉しいのは間違いないのですが、素直に喜べない要素が多いのが残念ですね。