概要
みなさんDirectMLってご存知ですか?私は今日知りました。その派生Projectのtensorflow-directmlと一緒に。
まだブログに書いていませんが、実は最近Radeon RX6900XTをようやく買うことができ、RTX3080は売ろうと思ったけどTensorFlowは使いたい...。でもROCmは未だにRDNAに対応してないし…。と思っていたところ発見した代物。
DirectMLはMicrosoftが開発しているWindowsとWSLで動く機械学習向けAPIで、DirectX12を介してGPUにアクセスするのでCUDAを使わずにGPUを機械学習用途に使えるというスグレモノ(という認識。まだちゃんと調べられてない)。
github.com
そしてtensorflow-directmlはそのdirectmlを利用したTensorFlowのフォークプロジェクト。TF1.15互換で作られており、インストールすると普通のtensorflowとして呼び出せます。TensorFlow2.xへの対応は1.15のプロジェクトが安定したら取り掛かるっぽい感じですので、しばらくは1.15互換で使うことになりそう。
※ 2022/06/23 追記: TensorFlow2対応のDirectML Pluginが公開されました。詳しくはこちらから。 https://hashicco.hatenablog.com/entry/2022/06/23/201222
github.com
機能はまだすべてを網羅しているわけではなく、演算の一部でDirectMLを使えるように調整されているそうです。(TensorFlowに存在する約1100の演算のうち、420をtensorflow-directmlで実装済み。通常のTensorFlowでGPUを利用できる演算は600程度らしいのでそこそこのカバー率? 参考:Roadmap · microsoft/tensorflow-directml Wiki · GitHub)
これのすごいところは、DX12が使えるデバイスであればいろんなCUDA非対応のGPUでもTensorFlowに使えること。
GitHubのReadmeに書かれているところでは、下記のグラボを使用可能とのこと。
つまりは、WindowsユーザーでRadeonやIntelのオンボしかGPUを持ってない人がなんとかTensorFlowを早くしたい!というときに使えるパッケージです。 (RadeonでもVega使ってる人ならLinux+ROCmが第一選択かも?)
ちなみにGeForceであればCUDA ToolkitやcuDNNのインストール無しでGPUを使ってTensorFlowを実行できます!すごい楽ちん!
ただもちろんCUDAを使うよりは遅くなるそうなので、あまりNvidiaユーザーには関係がないかも。また、当然まだPre-releaseなので動作が安定しないこともあるようです。
これを使ってDeepLabCutというTensorFlowを利用した動物の行動解析ソフトを動かしてみたら、なんと未だ動作確認のないRTX3080でもRX6900XTでもあっさり動いたので、そのログをつらつらと書いていきます。
www.mousemotorlab.org
環境
- Windows10 1909
- Python 3.6.8 virtualenv (DirectMLのPython対応は3.5, 3.6, 3.7のいずれか)
- RX6900XT -> ドライバ:20.12.2
- RTX3080 -> ドライバ:461.09
Microsoft公式の情報は、GitHubかMicrosoftDocsにあります
docs.microsoft.com
DirectMLのインストール
1. まずはPythonの仮想環境を作ります。私はAnaconda使うのやめたのでvirtualenv使います。
- Anacondaは商用利用無料じゃなくなったから職場で使えなくなったのよね……。もともとpipとの共存に難有りだったから脱出しようと思ってたし、いい機会だったのだけれども。
# 別にディレクトリ作らなくてよければ上2つはいらない
mkdir pyenvs
cd pyenvs
# dlcという名前のディレクトリの中に仮想環境ができます。
python -m virtualenv dlc
2.仮想環境に入る
# activate.batまでのパス。環境によって異なります。
dlc\Scripts\activate.bat
3.tensorflow-directmlのインストール。pypiに登録されてるのでただpipで入れるだけ
pip install tensorflow-directml
4.DeepLabCut関連のインストール。いらない人は入れなくていい。DirectMLで入ったnumpyのバージョンが下がるけど普通に動いたのでヨシ!
pip install wxpython==4.0.7
pip install deeplabcut==2.2b8
DirectMLの確認
pythonシェルに入って以下のコマンドを順番に実行。tensorflow-directmlは普通にTensorFlow(1.15)としてインポートできます。
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 124102394085376839
, name: "/device:DML:0"
device_type: "DML"
memory_limit: 14563195084
locality {
}
incarnation: 5023574286020867491
physical_device_desc: "{\"name\": \"AMD Radeon RX 6900 XT\", \"vendor_id\": 4098, \"device_id\": 29631, \"driver_version\": \"27.20.14501.33001\"}"
]
こんな感じでDMLというデバイスとしてRX6900XTが認識されています。RTX3080も似たような感じで見えます。オンボのGPUがあるときはそちらも表示されるはず。
公式ドキュメントのテストスクリプトを実行するとこんな感じ。ちゃんとDMLを利用して計算しているようです。
import tensorflow.compat.v1 as tf
tf.enable_eager_execution(tf.ConfigProto(log_device_placement=True))
print(tf.add([1.0, 2.0], [3.0, 4.0]))
2021-01-18 22:03:02.061475: I tensorflow/stream_executor/platform/default/dso_loader.cc:98] Successfully opened dynamic library C:\Users\Owner\pyenvs\dlc\lib\site-packages\tensorflow_core\python/directml.bdb07c797e1af1b4a42d21c67ce5494d73991459.dll
2021-01-18 22:03:02.071278: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:126] DirectML device enumeration: found 1 compatible adapters.
2021-01-18 22:03:02.073470: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2021-01-18 22:03:02.076668: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:109] DirectML: creating device on adapter 0 (AMD Radeon RX 6900 XT)
2021-01-18 22:03:02.131766: I tensorflow/core/common_runtime/eager/execute.cc:571] Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([4. 6.], shape=(2,), dtype=float32)
DeepLabCutでDirectMLを使ってみる
さてここからはDirectMLを使ってDeepLabCutを使ってみるという話。
Windowsなので普通にGUIを使って行きます。
import deeplabcut
deeplabcut.launch_dlc()
これでGUIが起動するので、いつもどおり設定ファイル書いたりラベリングしたりしてから、Train networkしていきます。
DeepLabCutの今回の設定では、内部的にImagenet学習済みのResNet50の転移学習をしています。
1280x720, 20枚の画像をラベリングし、学習に使用しました。1iterの学習に必要な時間を各GPUで測定し比較してみました。
昔同じデータセットを機械学習マシン(過去記事参照。K40Mを載せたCentOS機)で学習させた事もあったので、そちらの結果も載せています。
CPU(windows10, Ryzen 5600X): 2.38 s/iter
K40M(linux, native CUDA, i5-6400): 0.337 s/iter
RTX3080(windows10, directml, 5600X): 0.138 s/iter
RX6900XT(windows10, directml, 5600X): 0.265 s/iter
まあいくらTeslaとはいえKepler世代と比較して、RTX3080がたったの2倍強しか速くなってないのは悲しい。GitHubのIssueに上がっていますが大体DirectMLを使ったときのパフォーマンス低下は2x-3xくらいとのこと。
RX6900XTは14万もしたのにそんなにK40M(1万ちょい)と変わらないじゃん!……と言いつつも、正直インストールもこんなにすんなり行って、ちゃんとCPUよりも早く学習動くならなんにも文句言えないですね。
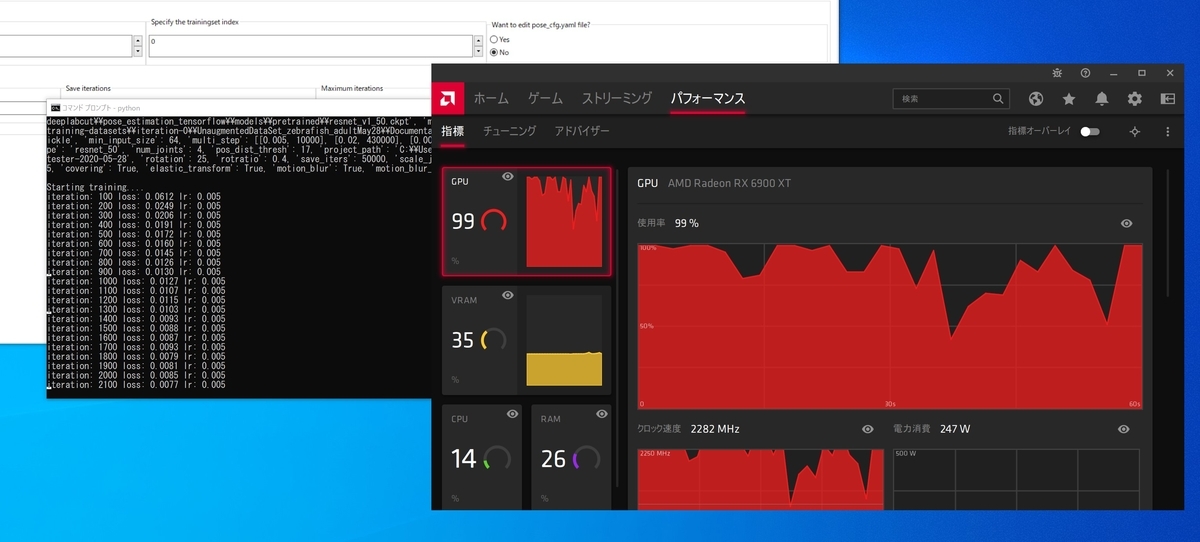
学習中はきちんとGPU使用率が上がってます。
あとがき
いやーびっくりです。まさかRadeonでこんなに簡単にTensorFlowが動くとは……。DirectML素晴らしい。
DX12を使ってハードウェアOpenで機械学習のアクセラレーションができるAPI、というのもとてもいい発想ですねDirectML。これをDirectXの本家本元のMicrosoftが主導しているというのも将来性が感じられて良き。まあDXなので代わりにWindowsに縛られることになるんですが…
これがもっと進化すればCUDAを打ち崩すこともできるのかしら。CUDAに縛られてNvidia一強というのは市場的にも健全じゃない気がするので、ROCmとかこのDirectMLみたいな取り組みには頑張ってもらいたいものです。
エラー出たのでどうにかした話
Tensorflow-Directmlで`DXGI_ERROR_DEVICE_REMOVED`が出てしまうときの対処法 - 端の知識の備忘録
修正
211203 TF互換が1.5と記載されていたのを1.15に訂正しました